At present many open source distributed processing systems such as Cloudera, Apache Storm, Spark and others support the integration with Kafka. Kafka is increasingly being favored by many internet shops and they use Kafka as one of its core messaging engines. The reliability of the Kafka message can be imagined as a commercial-grade messaging middleware solution.
In this article, we will understand Kakfa storage mechanism, replication principle, synchronization principle, and durability assurance to analyze its reliability.
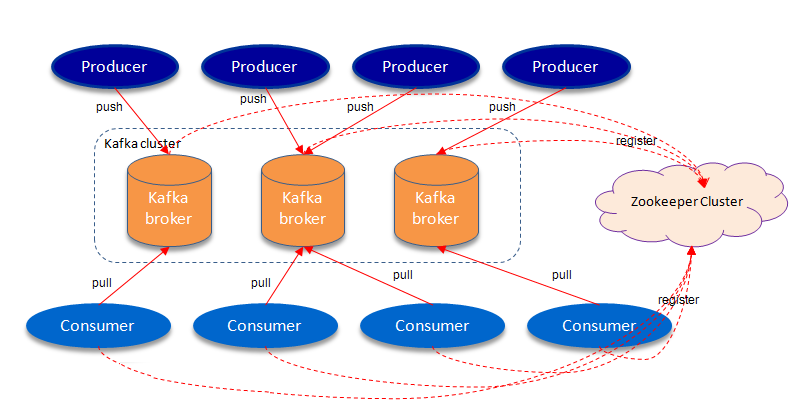
As shown in the figure above, a typical Kafka architecture includes several Producers (which can be server logs, business data, page views generated by the front-end of the page, etc.), several brokers (Kafka supports horizontal expansion, more general brokers), several Consumer (Group), and a Zookeeper cluster. Kafka manages the cluster configuration through Zookeeper, elects the leader, and rebalances when the consumer group changes. Producer uses push mode to post messages to brokers, and Consumer uses pull mode to subscribe and consume messages from brokers.
Topics and Partitions
Partition is a physical concept, and the topic is a logical concept. Each message posted to the Kafka cluster has a category, this category is called Topic, each topic will be divided into multiple partitions, each partition is the append log file at the storage level. The location of each message in the file is called offset, and offset is a long type number that uniquely identifies a message.
As we all know that sequential write disks are more efficient than random write memory. For Kafka’s high throughput, each message is appended to the partition, which is a sequential write to disk and is therefore very efficient.
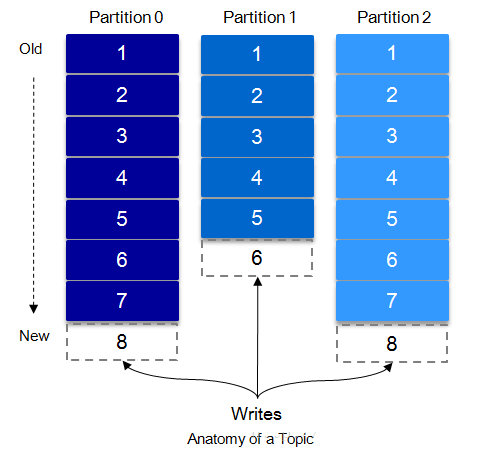
Partitions solve the problem of the performance bottleneck. By setting the partition rules, all messages can be evenly distributed to different partitions, thus achieving a level of expansion. When creating a topic, you can specify the number of partitions in $KAFKA_HOME /config/ server.properties, and of course, you can change the number of partitions after topic creation. When sending a message, you can specify the key of this message, according to the key and the partition mechanism to determine the producer of this message sent to which partition.
Kafka’s high reliability is guaranteed by its robust replication strategy.
We have reached the point where we can start exploring the Kafka concept of macro level by explaining Kafka’s replication principle and synchronization method. Now, lets start exploring Kafka from various dimensions, such as ISR(In-Sync Replicas), HW(HighWatermark), leader election and data reliability and durability assurance.
How the topic and how the partition is stored?
Messages in Kafka are classified by topic. Producers send messages to Kafka brokers over topics, and consumers read data through topics. A topic can be divided into several partitions and the partition can be subdivided into multiple segments thus a partition physically composed of more than one segment.
For the sake of illustration, I’ll show here the files present on my single node cluster has only one Kafka Broker. Location of the Kafka message file storage directory is below:-

You can changes location of kafka-logs directory by setting the “server.properties” file in $KAFKA_HOME/config location. Let us suppose if partition is the smallest storage unit, we can imagine that when Kafka producer keeps sending messages, it will inevitably cause infinite expansion of partition file, which will seriously affect the maintenance of message files and the clearing of consumed messages. Therefore the segmentations where partition can be subdivided into segment. Each partition is equivalent to a giant file is equally divided into multiple equal size segment (segment) data file (the number of messages in each segment file is not necessarily equal). Segment file life cycle can be changed by the modifying the server configuration parameters (log.segment.bytes, log.roll.).
Segment file consists of two parts, namely “. Index” file and “.log” file, respectively, as the segment index file and data file.

The “.index” Index file stores a large amount of metadata, “.log” data file stores a large number of messages, metadata in the index file points to the physical offset address of the message in the corresponding data file. The naming convention of these two files are as follows: partition The first segment starts from 0, each subsequent segment file name is the offset value of the last message of the last segment file, the value is 64 bits, the length of 20 digits characters, No numbers are padded with 0.

As shown above, we have 170410th segment with 0000000000000170410.index and 0000000000000170410.log file. Taking the example of metadata [3, 348] in the “.index”, the third message is represented in the “.log” data file, that is, 170410 + 3 = 170413 messages in the global partition, The physical offset is 348 in local segment file.
How to find the message from the partition offset?
Let’s say we have below files in particular segment and we want to read offset = 170418 message. First find the segment file, where 00000000000000000000.index for the beginning of the file, the second file is 00000000000000170410.index (starting offset 170410 +1 = 170411), and The third file is 00000000000000239430.index (the starting offset is 239430 + 1 = 239431), so this offset = 170418 falls into the second file.

Replication and synchronization
Kafka has N replicas for each topic partition in order to improve message reliability, where N (greater than or equal to 1) is the number of topic replica factor. Kafka automates failover with a multi-copy mechanism and guarantees that services are available when a broker in a Kafka cluster fails. In Kafka N replicas, one of the leaderr replica, others are follower, leader to deal with all the partition read and write requests, at the same time, follower passively and regularly to copy the data from the leader.
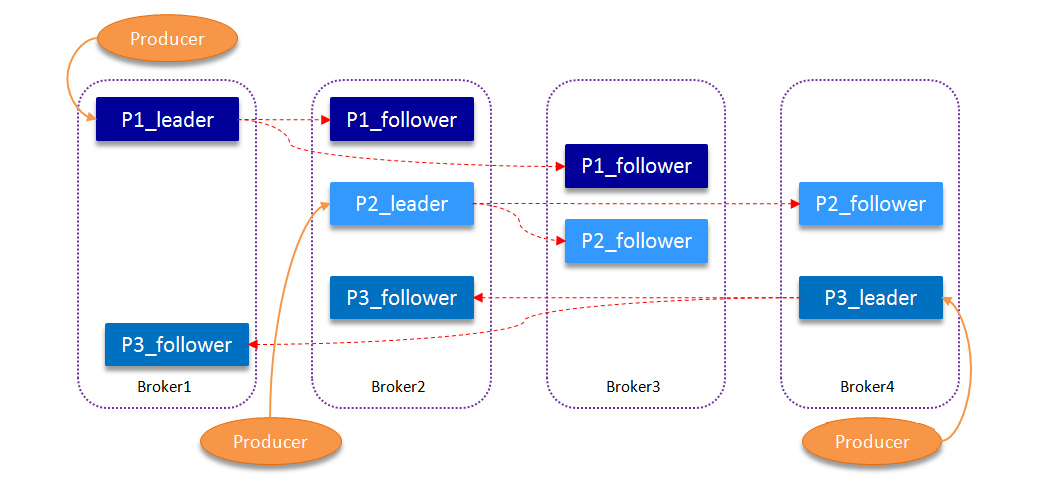
Kafka provides a data copy algorithm to ensure that if the leader fails or hangs up, a new leader is elected and the message to the client is successfully written. The leader is responsible for maintaining and tracking the status of all follower lags in the ISR (In-Sync Replicas) indicating a copy synchronization queue. When the producer sends a message to the broker, the leader writes the message and copies it to all the followers. The message was successfully copied to all synchronized copies after it was submitted. Message replication latency is limited by the slowest follower, and it is important to detect slow copies quickly, and the leader will remove it from the ISR if the follower “lags” too much or fails.
The replica.lag.max.messages parameter was removed after version 0.10.x of Kafka, leaving only replica.lag.time.max.ms(delay) as a parameter for replica management in ISR. Setting too large for replica.lag.max.messages, affecting the real “behind” follower removal; set too small, resulting in frequent follower access(performance issue). Let us see the problem, replica.lag.max.messages said that, if the current number of copies of leader message exceeds the value follower massages of this parameter, then the leader will remove follower from the ISR. Suppose you set replica.lag.max.messages = 4, if the number of messages sent to the broker by the producer is less than 4 at a time, the follower lags behind after the leader receives the message from the producer and the follower’s copy begins to pull those messages Leader of the number of messages will not exceed 4 messages, so there is no follower removed from the ISR, so this time replica.lag.max.message set seems to be reasonable. However, the producer initiates an instantaneous peak flow, and when the producer sends more than 4 messages at one time, that is more than replica.lag.max.messages, the follower is considered to be out of sync with the leader and is thus the follower kicked out of the ISR. But in fact these followers are alive and have no performance issues. Then soon they catch up with the leader, and re-
joined the ISR. As a result, they constantly tick out ISRs and return to ISRs again, which undoubtedly adds unnecessary performance overhead.
The above section also refers to a concept, HW. HW commonly known as high water level, take a partition corresponding to the smallest of the ISR LEO(Log End Offset) as HW, consumer can only consume the HW where the location. In addition, each replica has HW, leader and follower are responsible for updating their HW status. For the newly written message of the leader, the consumer cannot consume it immediately. The leader will wait for the message to be updated after all the replicas in the ISR have been synchronized.
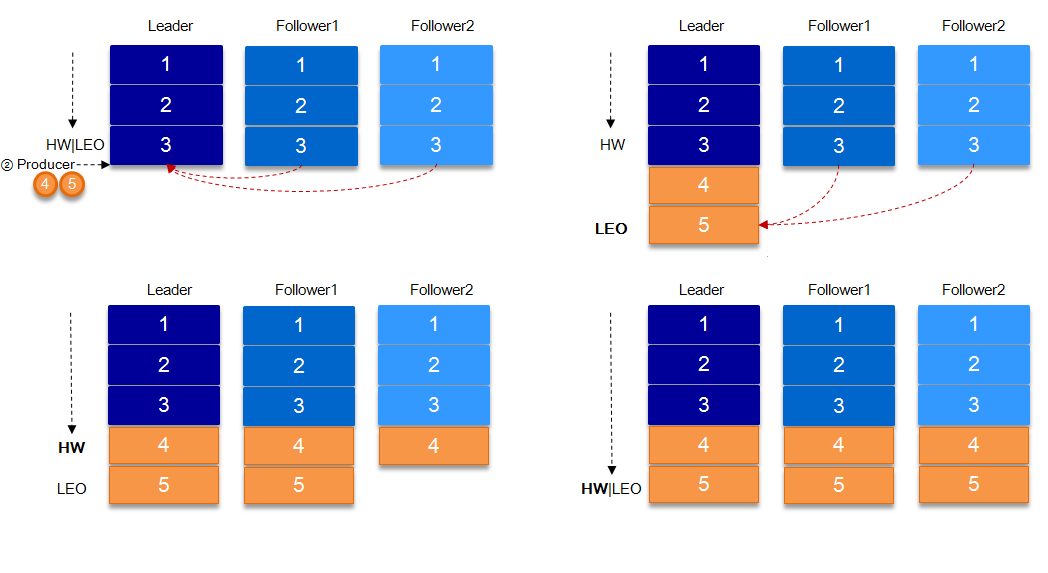
The request.required.acks parameter to set the level of data reliability:
1 (default): This means that the producer sends the next message after the leader has successfully received the data in the ISR and is confirmed. If leader is down, it will lose data.
0: This means that the producer does not need to wait for confirmation from the broker to continue sending the next batch of messages. In this case the most efficient data transfer, but the reliability of the data is indeed the lowest.
-1: The producer needs to wait for all the followers in the ISR to confirm that the data is sent once after the data is received, which has the highest reliability. However, this does not guarantee that the data will not be lost.
If you want to improve the reliability of the data, set the request.required.acks = -1, but also min.insync.replicas this parameter (which can be set in the broker or topic level) to achieve maximum effectiveness. This parameter sets the minimum number of copies in the ISR. The default value is 1. This parameter takes effect if and only if the request.required.acks parameter is set to -1. Clients will return an exception if the number of copies in the ISR is less than the min.insync.replicas configuration: org.apache.kafka.common.errors .NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required.
Thanks:Mukesh Kumar
No comments:
Post a Comment